Stapel (Stack)
Klassisches Beispiel für lineare Datenstruktur: (Keller-)Stapel
Funktionsweise zur Genüge bekannt (→ Kapitel Zeiger)
→ Hier nicht noch mal Thema
- Stattdessen: Typische Operationen der zugrundeliegenden Datenstruktur
push: legt Element oben auf den Stapelpop: entfernt oberstes Element vom Stapeltop: gibt das oberste Element vom Stapel zurückempty: prüft, ob Stapel leer istsize: gibt Anzahl der Elemente zurück
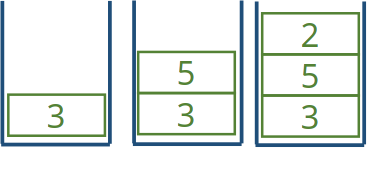
- Arbeitsprinzip: Last In, First Out (LIFO)
Warteschlange (Queue)
- Weitere, verbreitete Datenstruktur: Warteschlange (Queue)
- Typische Operationen
enqueue: fügt Element hinten andequeue: entfernt vorderstes Elementfront: gibt vorderstes Element zurückback: gibt letztes Element zurückempty: prüft, ob Warteschlange leer istsize: gibt Anzahl der Elemente zurück
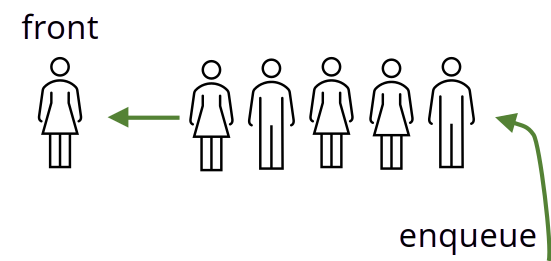
- Arbeitsprinzip: First In, First Out (FIFO)
Bäume
- Häufig verwendete Datenstruktur
- Zahlreiche Anwendungen
Suchen von Elementen
→ B-Trees (Datenbanken), Rot-Schwarz-Bäume
Aufteilen von Raum
→ Binary Space Partitioning (z.B. in Videospielen)
Min-/Max-Heaps
→ Grundlage von Prioritätswarteschlangen
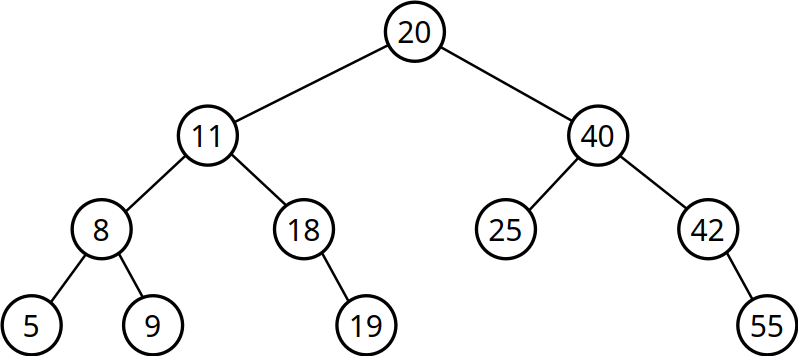
- Hier und heute: Binärbaum - einfachste Form eines Baums
Binärbäume
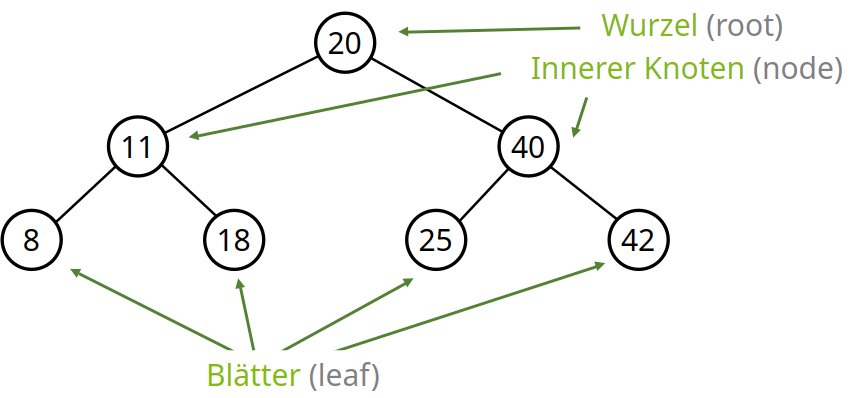
- Besteht aus Knoten (Nodes)
- Startknoten → Wurzel des Baums (Root)
- Endknoten → Blätter des Baums (Leafs)
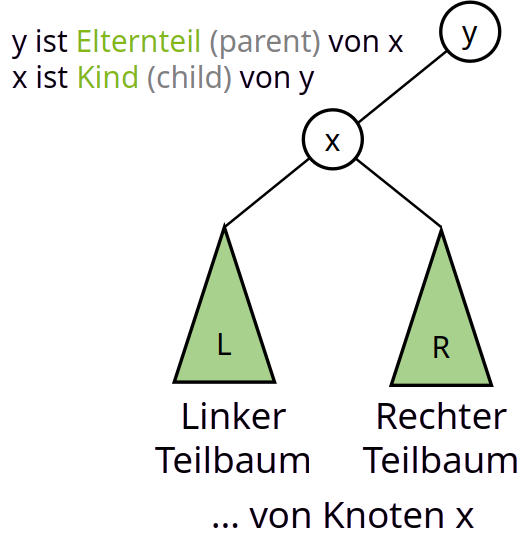
- Vorgängerknoten → Elternteil (Parent)
- Nachfolgeknoten → Kind (Child)
- Jedem Knoten wird ein Wert zugewiesen
- Jeder Knoten hat höchstens zwei Kindknoten → binär
- Suchbaumeigenschaft
- Linkes Kind ist kleiner
- Rechtes Kinds ist größer
Eigenschaften von Binärbäumen
Wurzel hat keine Vorfahren
Blätter hingegen haben keine Kinder
→ Linkes und rechtes Kind
Darf aber auch nur einen/keinen Kindknoten besitzen
Pfad: Folge von zusammenhängenden Eltern-Kind-Knoten
Definition erfolgt rekursiv
Höhe eines Baumes
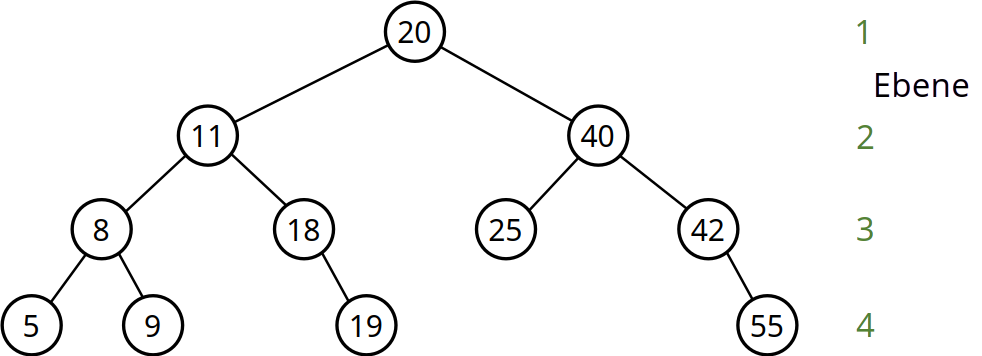
- Höhe eines Baums ist die Anzahl der Knoten auf dem längsten Pfad im gesamten Baum
- Betrachung von Wurzel zu Blatt
- Höhe eines leeren Baums:
0, da keine Knoten vorhanden - Beispiel: \(20,40,42,55\)
Größe eines Baumes
- Ebene \(k\): Knoten mit Abstand \(k-1\) zur Wurzel
- Auf Ebene \(k\) können jeweils zwischen \(1\) und \(2^{k-1}\) Elemente liegen
- Max. Anzahl Elemente bei Höhe \(h\): \(\sum_{k=1}^{h} 2^{k-1} = 2^h -1\)
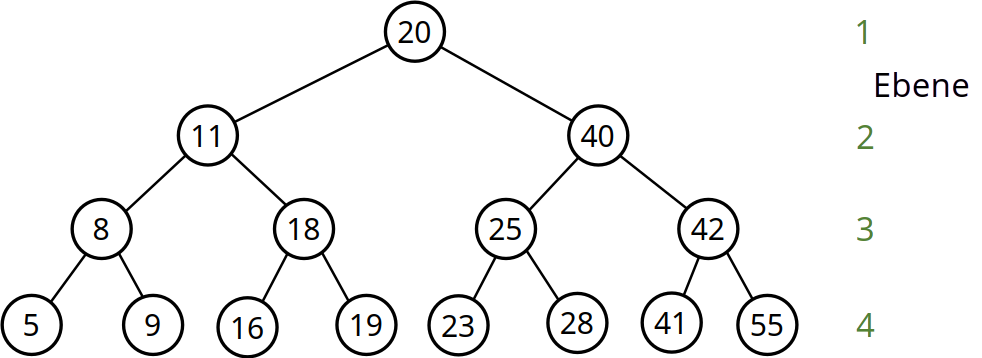
Eigenschaften von Binärbäumen
- vollständiger Baum der Höhe \(h\) besitzt \(2^h-1\) Knoten
- Sei \(n = 2^h-1\): Dann braucht man höchstens nur \(\lceil log_2(n)\rceil\) Schritte, um ein Element zu suchen!
- Beispiel: \(n=100 \Rightarrow \lceil log_2(100)\rceil = \lceil 6.64\rceil = 7\)
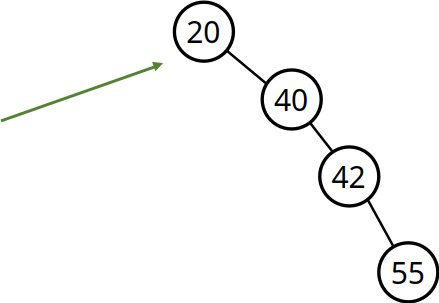
- Degenerierter Baum
- Aus Baum wird eine Liste
- Bei \(n\) Knoten wären dann wieder \(n\) Vergleiche notwendig (\(O(n)\) statt \(O(log{}\text{ }n\)))
- Ein extremes Gegenbeispiel (Worst Case) → entspricht Liste
Vorteile von Binärsuchbäumen
- Erlaubt schnelle Suche
- Ablauf
- Falls gleich → Ende der Suche, alle sind glücklich
- Ansonsten
- Gesuchtes Element ist kleiner → nach Links
- Gesuchtes Element ist größer → nach rechts
- Großartige Eigenschaft: Bei Auswahl des nächsten Teilbaums fallen alle anderen Teilbäume weg
- Bei (balancierten) Binärbäumen halbiert sich der verbleibende Suchraum im besten Fall automatisch
Beispiel - Durchlaufstrategien
- Für Tiefensuche (DFS): Rekursion verwenden
- Breitensuche (BFS) verwendet hingegen eine Warteschlange (hier nicht dargelegt)
Beispiel - Durchlaufstrategien
- Je nach Strategie andere Ausgabe:
- Preorder: \(20, 11, 8, 5, 9, 18, 19, 40, 25, 42, 55\)
- Inorder: \(5, 8, 9, 11, 18, 19, 20, 25, 40, 42, 55\)
- Postorder: \(5, 9, 8, 19, 18, 11, 25, 55, 42, 40, 20\)
Beispiel - Durchlaufstrategien
- Praktische Anwendung:
- Erstellen einer Kopie (Preorder)
- Ausgabe des Baums (Inorder)
- Löschen des Baums (Postorder)
Dictionary
Speichern für jeden Hash assoziierte Daten
Hashkollisionen: Erstellen einer Linked-List für diesen Hashwert
Gute Hashfunktion → wenig/keine Kollisionen
Unwahrscheinliche Kollision
→ i.d.R. wenige Schritte für Nachschlagen
→ konstante Zeit
Dictionaries sind gut für schnelles und zuverlässiges Nachschauen geeignet

Exkurs: Graphen
- Weiteres großes Gebiet der Mathematik und Informatik: die Graphentheorie
- Ein Graph ist eine abstrakte Struktur, die verschiedene Objekte (Knoten) miteinander über Kanten verbindet
- Einfache Anwendungsbeispiele
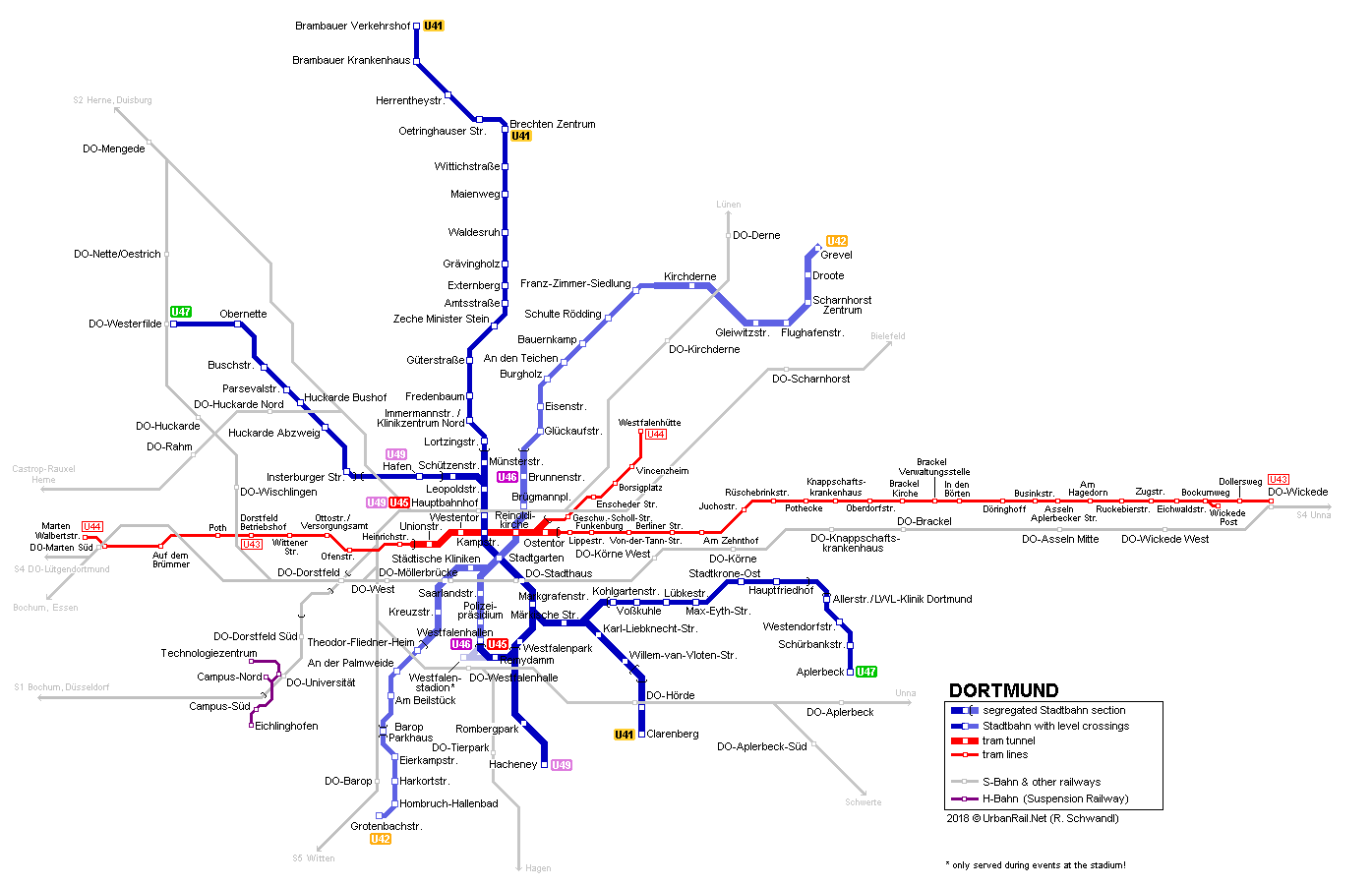
- Navigation → Straßenbahn und Verkehr
- Netzwerke → Computernetzwerke/Internet, aber auch Funkverbindungen (z.B. überlappendes Mobilfunknetz)
- Soziale Netzwerke → Abbildungen von Interaktionen und Gruppen (Social Media Bubbles)
- Layout-Fragen bei elektronischen Schaltungen
Übrigens: Ein Binärbaum ist auch nur ein spezieller Graph 😊
Beispiele für Graphen
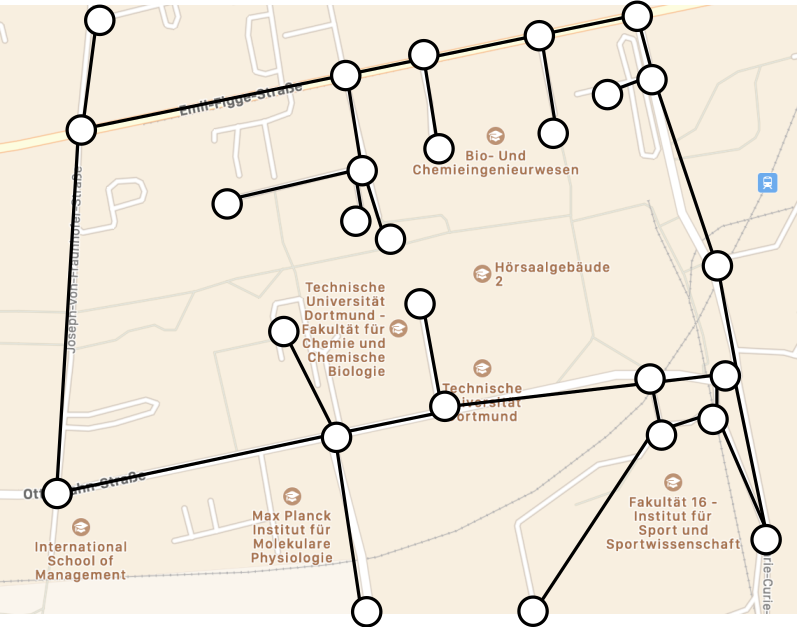
- Einfaches Beispiel: Nord-Campus als Graph
- Kreuzungen sind Knoten, Straßen sind Kanten
Beispiele für Graphen
- Graphen sind sehr vielseitig: Chemische Verbindungen als Graph darstellbar
- Beispiel: Koffein als Graph dargestellt
- Atome → Knoten, Bindungen → Kanten


{kind=link}
Definition von Graphen
- Graph \(G = (V,E)\) besteht aus
- einer Menge \(V\) von Knoten (Vertex bzw. Plural Vertices) und
- einer Menge Kanten \(E\) (Edges) mit \(E \subseteq V \times V\) (→ „jedes E wird aus zwei V gebildet”)
- \(V = \{1,2,3,4,5\}\)
- \(E = \{(1,2),(1,5),(2,3),(2,5),(3,3),(3,4),(3,5),(4,5)\}\)
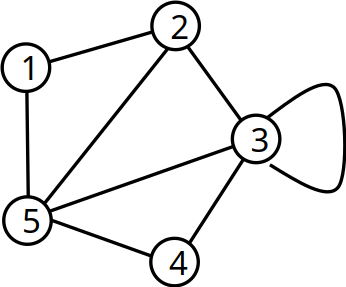
- Grad (degree) eines Knotens \(v \in V\) ist die Anzahl an adjazenten Knoten
- Mit anderen Worten: Alle zu \(v\) durch eine Kante verbundenen Knoten sind adjazent
- Beispiel: \(deg(5) = 4\) → „5 hat vier Nachbarn”
Speicherung von Graphen
- Abschließend: Exemplarische Speicherung von Graphen
- Zwei Möglichkeiten: Adjazenzliste oder Adjazenzmatrix
- In der Praxis: Adjazenzliste, weil Matrix \(O(n^2)\) Speicher und Zeit braucht
- Außerdem: Viele Graphen haben Lücken (sparse) → viele
0in Matrix
- Adjazenzmatrix: Setze in 2D-Array bei Kante
1, sonst0
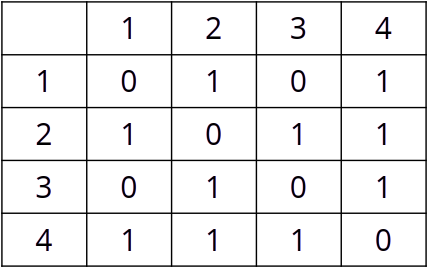
- Adjazenzliste: Erstelle für jeden Knoten Liste mit Nachbarn
Ausblick
Wir waren hiermit gestartet …
- Programmierung als Bindeglied
- zur echten Welt und
- praktische Umsetzung von theoretischen Problemen
- TODO Abschließende weise Worte
